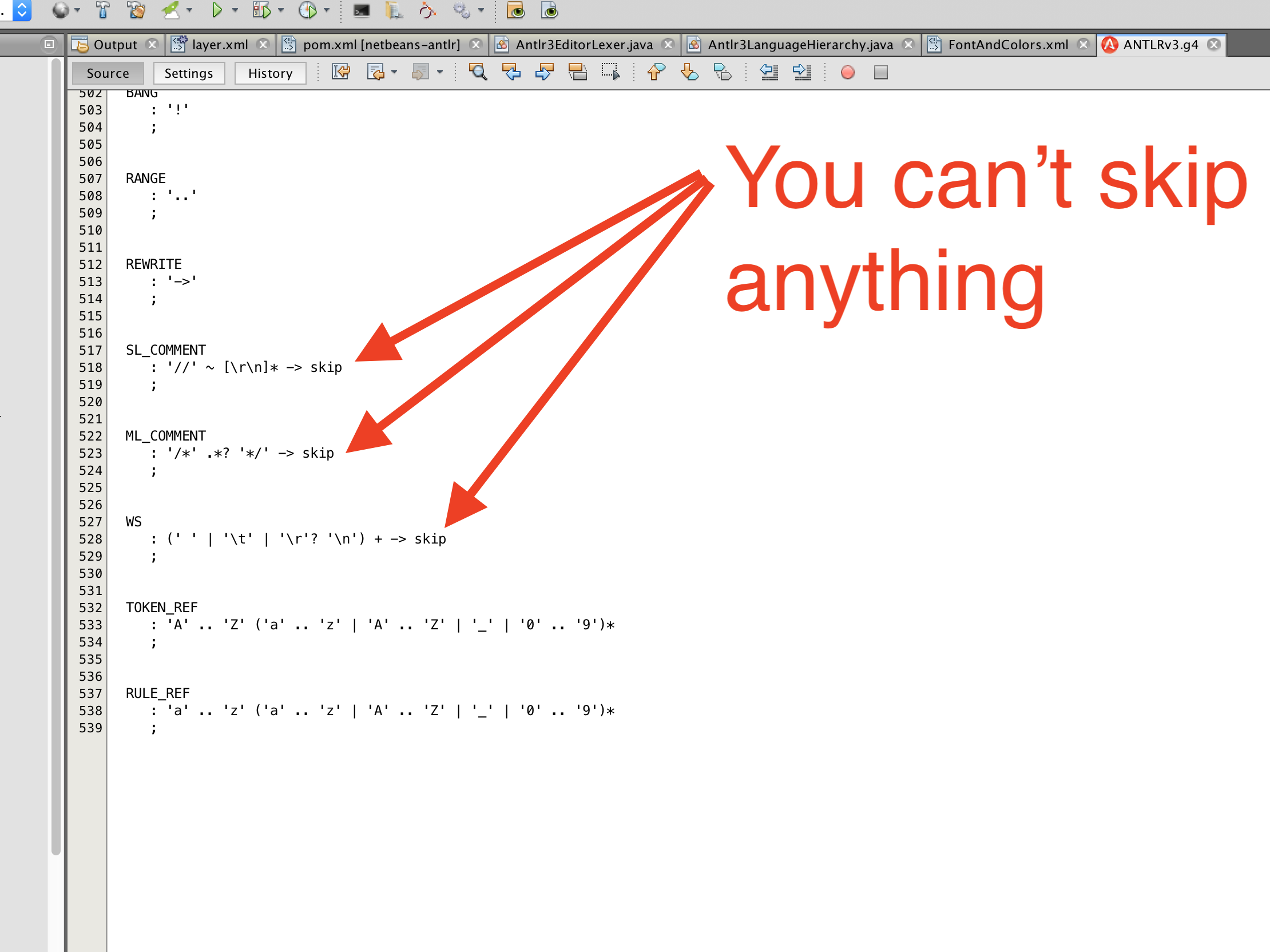
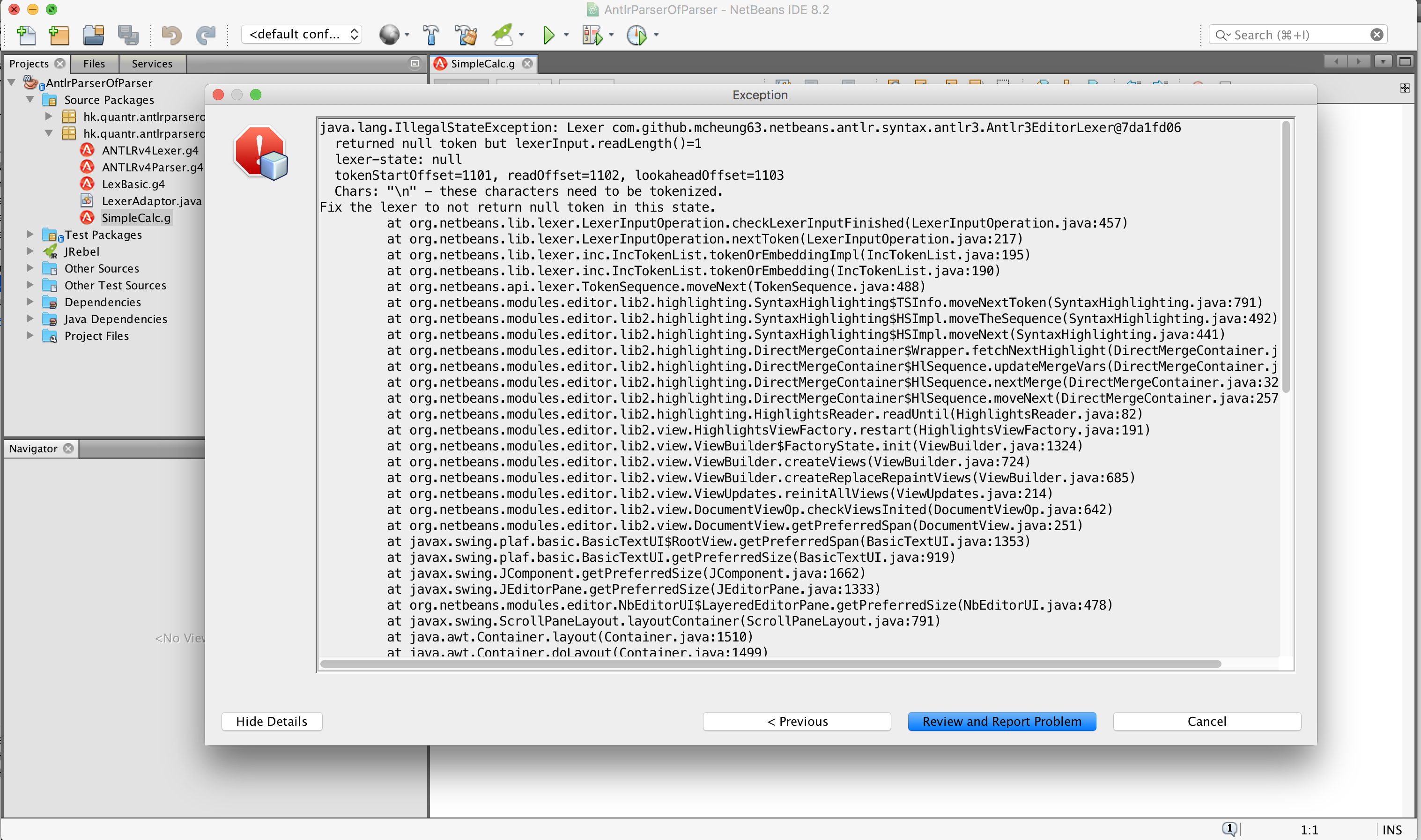
When developing highlight for new language, the antlr grammar has to return all tokens, you can’t skip token, otherwise your netbeans will throw this exception:
java.lang.IllegalStateException: Lexer com.github.mcheung63.netbeans.antlr.syntax.antlr3.Antlr3EditorLexer@7da1fd06 returned null token but lexerInput.readLength()=1 lexer-state: null tokenStartOffset=1101, readOffset=1102, lookaheadOffset=1103 Chars: "\n" - these characters need to be tokenized. Fix the lexer to not return null token in this state